

Wanna see a magic trick?
Wanna see a magic trick?
Prestidigitation, Legerdemain, and LLM Explainability

Disclaimer: The views and opinions expressed in this blog are entirely my own and do not necessarily reflect the views of my current or any previous employer. This blog may also contain links to other websites or resources. I am not responsible for the content on those external sites or any changes that may occur after the publication of my posts.
End Disclaimer

I got to see Ricky Jay perform before he died, in a beautiful, small performance space, on the Upper West Side of Manhattan. I had watched his David Mamet-directed “Ricky Jay and His 52 Assistants” and read his Learned Pigs & Fireproof Women: Unique, Eccentric and Amazing Entertainers . I’d never been to a live magic show before. He used words I hadn’t heard before like legerdemain and prestidigitation. He kept his sleeves up the whole time which I thought was a cool touch. He threw playing cards like knives. He made things disappear and reappear out of thin air. He was just so effortlessly cool. His magic was alchemy and transmutation.

Magic is part abstraction. No stepwise paths, no straight lines. Jumps and cuts, feints and flourishes. That night I paid rapt attention. I wanted the magic of the magic. And I got it.
Now, each day around the world, another type of magic trick is going on millions of times a day. People type or speak questions into their computers or phones, and answers pour out near instantaneously. Mind reading- a confabulation- what manner of magic is this?
Well, here’s the thing. I’ll let you behind the curtain, so to speak, into our llm “Circle of Trust”. After years of deployment, in natural language processing tasks and now more broadly tailored to be llm chatbots and “lite agents”, we still don’t have a way of knowing exactly how an llm came up with an answer at the atomic level.
Billions of dollars invested in the space to build foundational models, train them for months, run safety on them for months, and still many of their machinations and goings-on remain an abstraction, a sleight-of-hand, a prestidigitation. Ricky would be proud.
How did we get here, to where the output seems more like a magic trick than a calculation?
Well, it’s complicated.
Let’s explore some aspects why neural nets and LLMs are hard to explain and why more focus and resources are not being currently allocated to do so.
Now for my Equivoque (Magician's Choice)!
The Architecture
Neural networks output are hard to decompose back down to the root neuron level. For some types of machine learning algorithms like trees and forests you can sort of follow the pachinko ball through the nodes and branches for very good explainability. No so much with neural nets. Let’s go over how they work, while comparing them to the actual neural network found in brains.
1. Neurons
In the Brain:
Biological Neurons: About 86 billion neurons process and transmit information via electrical and chemical signals.
Structure: Includes a cell body, dendrites (receive signals), and an axon (sends signals).
In Neural Networks:
Artificial Neurons: Nodes or units in ANNs (Artificial Neural Networks) that process input and produce output through mathematical functions.
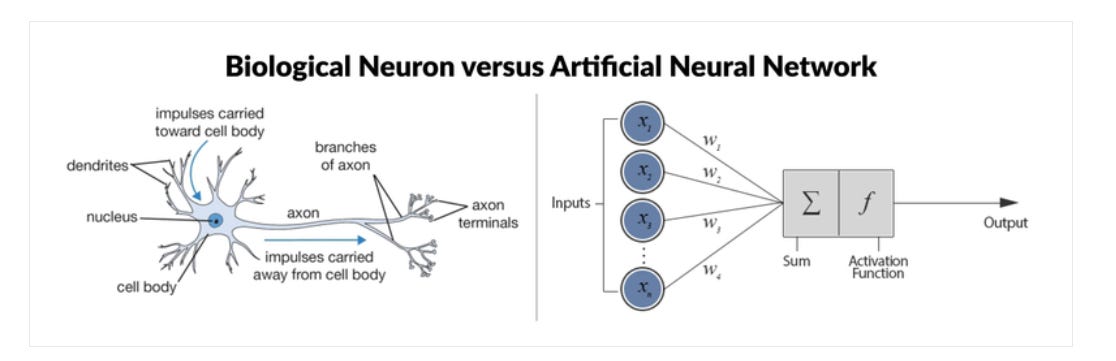
Structure: Consists of inputs with associated weights, a weighted sum, and an activation function to produce the output.(see picture above)
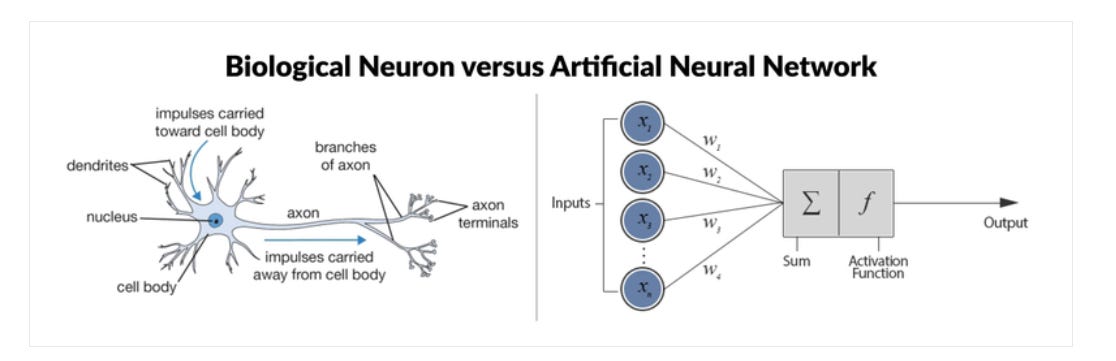
Image Credit: https://www.datacamp.com/tutorial/deep-learning-python
In the brain, a neuron fires when it receives enough electrical input to reach a threshold, generating an action potential that travels down its axon to transmit a signal to other neurons.
In neural networks, a neuron "fires" when the weighted sum of its inputs exceeds a threshold defined by an activation function(trigger mechanism), producing an output that is passed to subsequent layers in the network.
2. Synapses
In the Brain:
Synapses: Connections between neurons that transfer signals and undergo synaptic plasticity (strengthening or weakening).
In Neural Networks:
Weights: Represent the strength of connections between artificial neurons, adjusted during training via backpropagation.
3. Layers and Architecture
In the Brain:
Layers: Organized regions and layers specialized for different functions, with massively parallel processing.
In Neural Networks:
Layers: Comprise an input layer, hidden layers, and an output layer, transforming data into abstract representations. Includes architectures like CNNs and RNNs.
4. Activation and Propagation
In the Brain:
Electrical Signals: Action potentials propagate information, influenced by neurotransmitters.
In Neural Networks:
Activation Functions: Non-linear functions (where the output does not change in direct proportion to the input) like ReLU or sigmoid introduce complexity in learning patterns, with forward propagation through layers.
An activation function decides if a neuron should "fire" based on its input, much like a light switch turning on a light. This helps the neural network understand and learn complex patterns, similar to how different combinations of switches can create varied light patterns in a room.
Why are non-linear functions important in this context? Non-linear functions like the sigmoid are crucial in neural networks because they enable the network to model complex relationships and learn from data that cannot be separated by a straight line. This non-linearity allows the network to capture patterns and interactions in the data, making it possible to solve problems that linear functions alone cannot handle.
Types of Activation Functions- I circled 2 popular ones
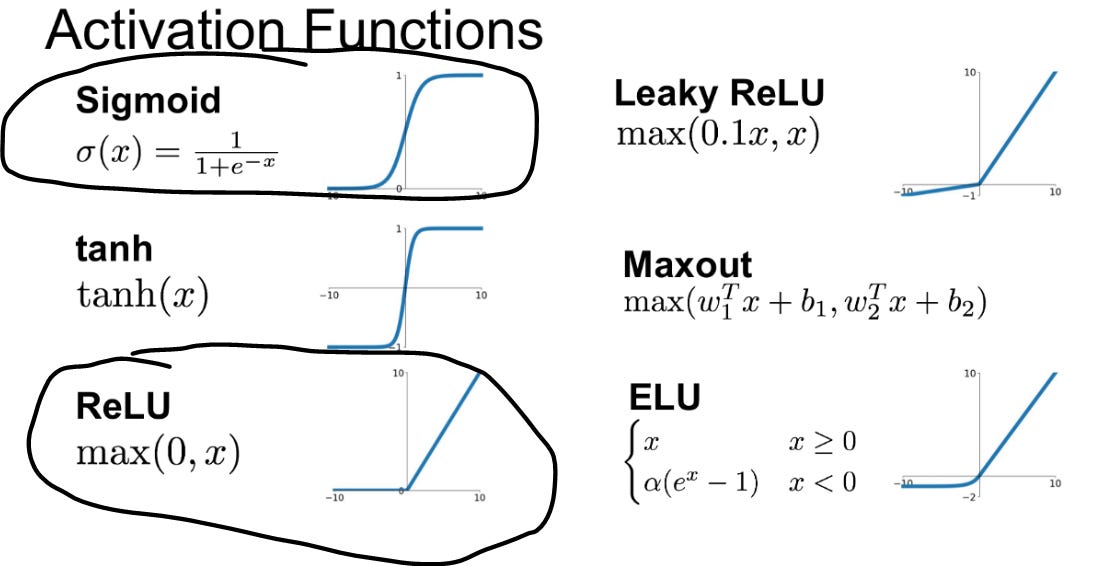
5. Learning Mechanisms
In the Brain:
Hebbian Learning: Strengthens connections between frequently co-activated neurons, contributing to neuroplasticity.
Hebbian learning can be summarized by the phrase "cells that fire together, wire together." Just like dance partners improve their coordination through synchronized practice, neural connections strengthen when neurons activate together frequently.
In Neural Networks:
Backpropagation: Adjusts weights to minimize error using gradient descent, learning from data patterns.
Backpropagation is used to compute the gradients of the loss function with respect to the weights, and gradient descent uses these gradients to update the weights in order to minimize the loss function.
Now- in english:
Backpropagation: Think of backpropagation as figuring out how much each weight in the neural network contributed to the overall error (or "loss"). It works backward from the output layer to the input layer, like tracing back your steps to find out where you went wrong.

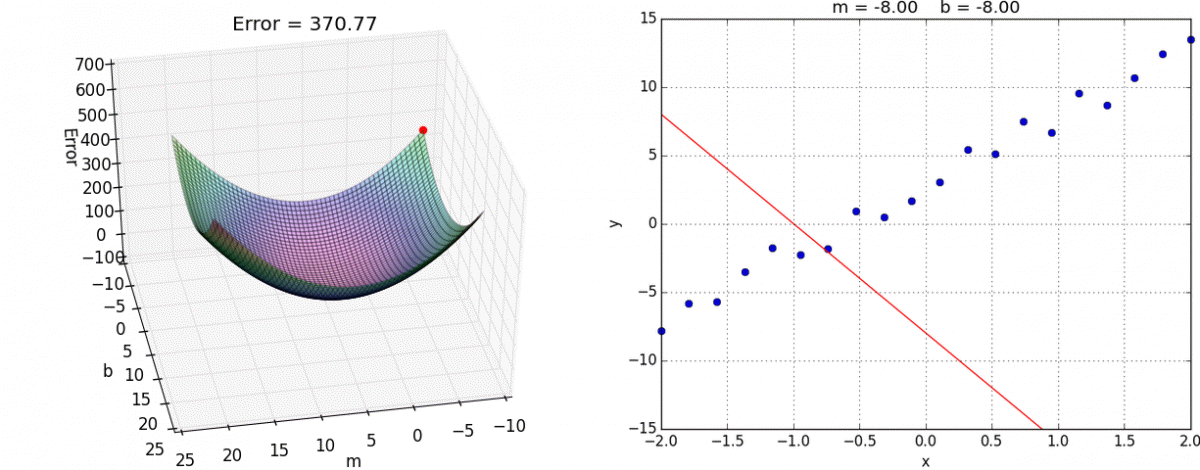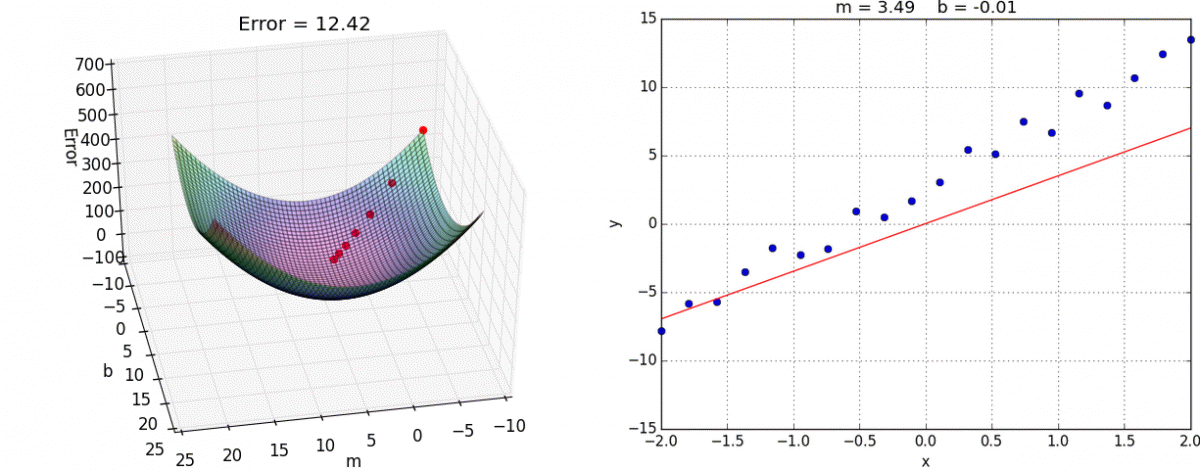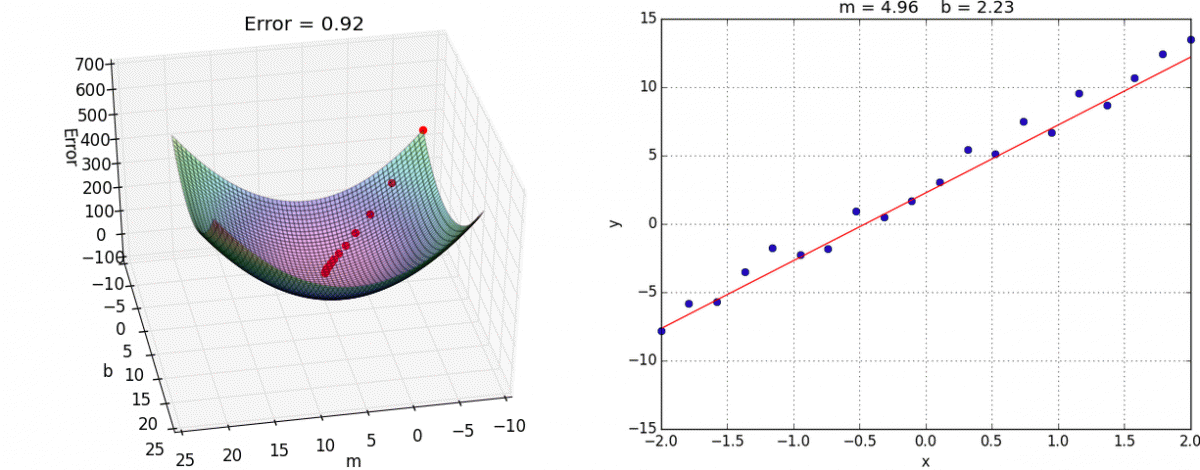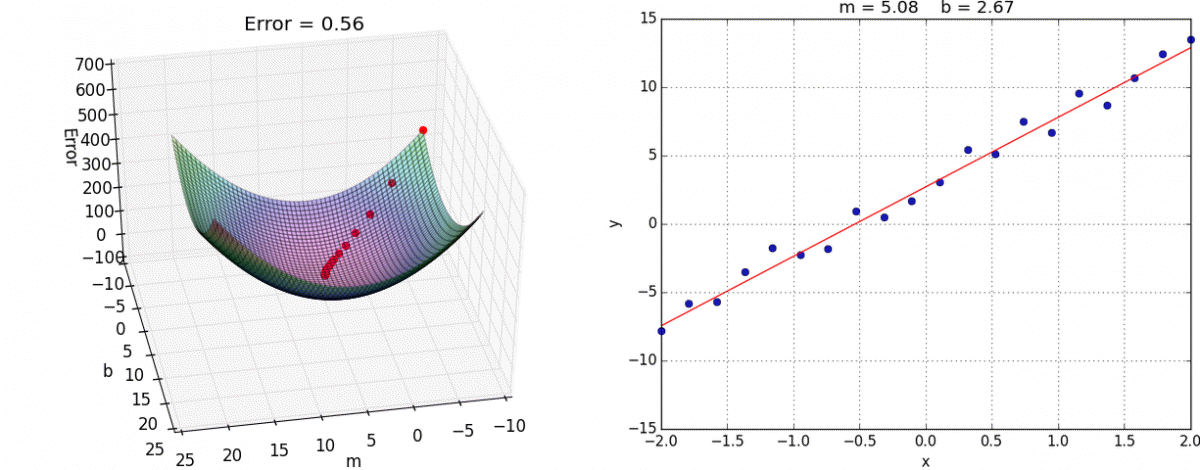
recognizing the number 5, image credit (and excellent videos): What is backpropagation really doing? | Chapter 3, Deep learning Gradient Descent: Once we know how much each weight contributed to the error (from backpropagation), gradient descent helps us adjust these weights to reduce the error. It does this by taking small steps in the direction that reduces the error the most, like walking downhill to reach the lowest point.
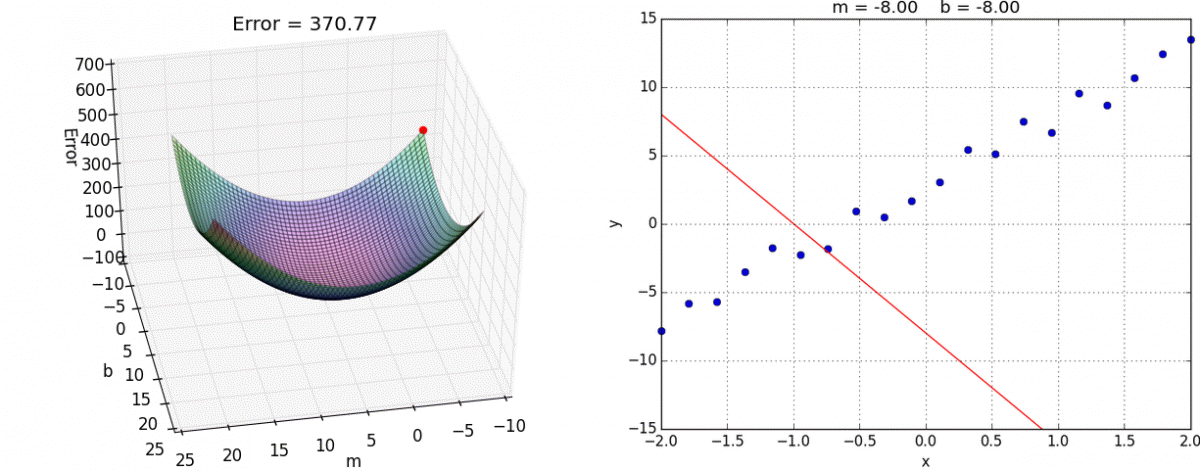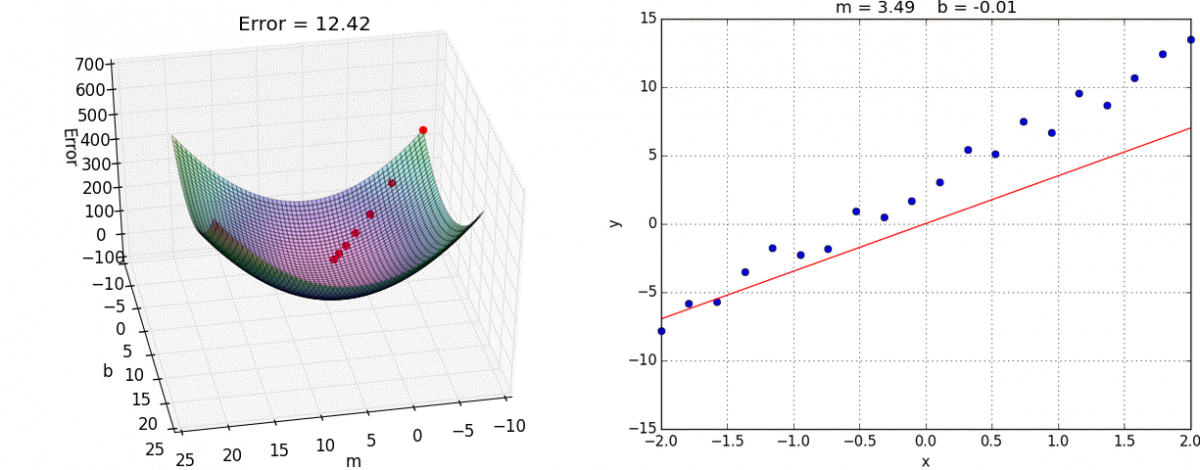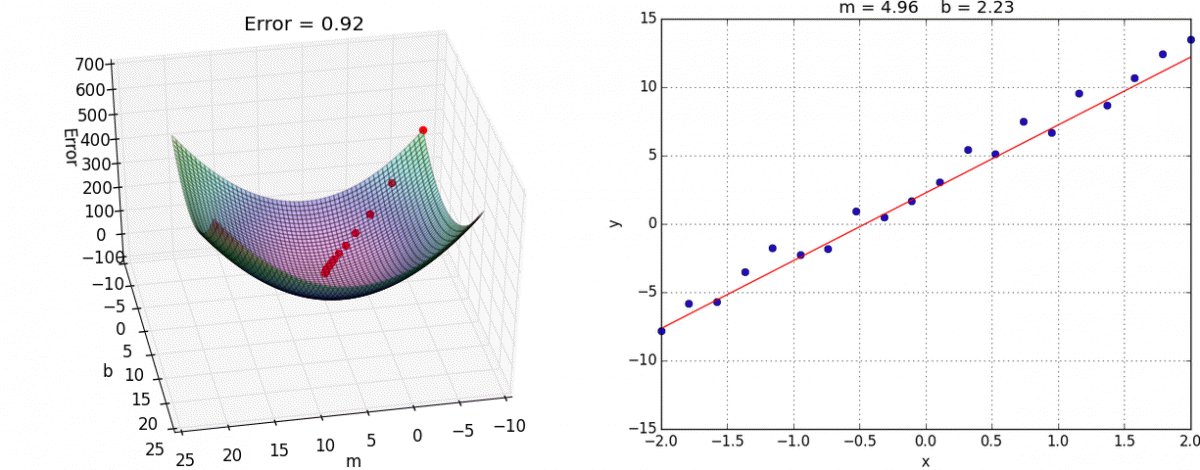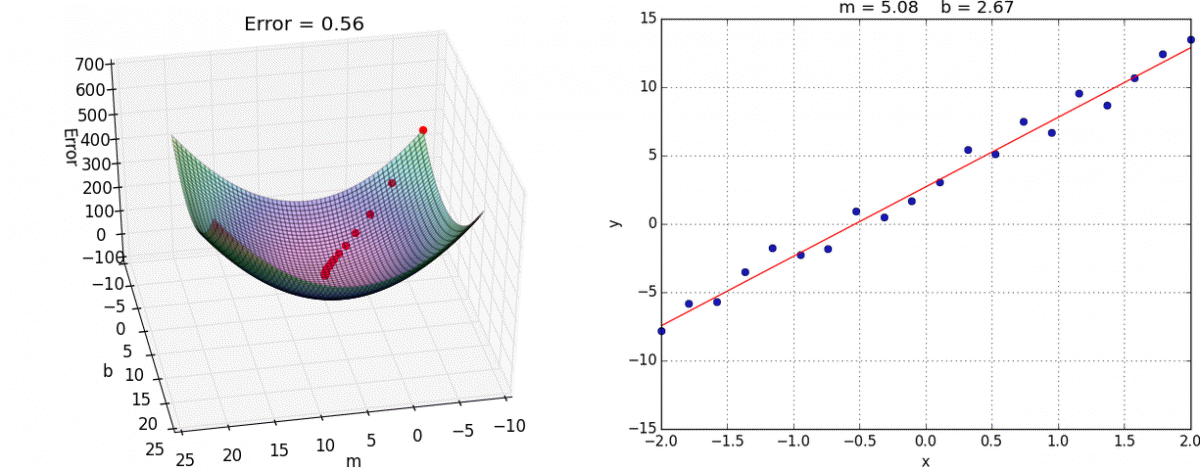
image credit: Gradient descent in Matlab/Octave Backpropagation tells us the direction to move to reduce error, and gradient descent takes us in that direction.

6. Memory
In the Brain:
Memory Types: Short-term and long-term memory, with the hippocampus crucial for long-term memory formation.
In Neural Networks:
Memory Mechanisms: Networks like RNNs and LSTMs retain information over time, storing learned information in weights and biases.
And…scene (Otakar bows in tophat and tails…)
Ok, so that’s how neural nets are similar to brains. They are the atomic level piece behind this whole “genAI” thing, so it’s important to have a working knowledge of what's going on.
Now we examine a wrinkle of this architecture that makes them difficult to decipher and interpret.
Polysemanticity
Polysemanticity- A particularly strong 2$ word that is also fun to say out loud. Try it now. I’ll wait. See what I mean? Same words can have different(many) semantic meanings. This concept has been on computational linguists’ radars for decades, and now becomes an important component of trying to disambiguate meaning down to the neuron level in machine learning:
We sat alongside the bank of the river.
I need to go to the bank to get my money.
On our approach to Burbank, the airplane had to bank sharply right.
It gets even more tricky because within neural net architecture polysemanticity also refers to the phenomenon where a single neuron or a single unit in the model’s architecture is responsible for encoding multiple, often distinct, concepts or meanings. This can occur because of the complex and high-dimensional nature of language data and the need for efficient representation learning within neural networks. These neurons can be activated by all the different meanings of bank above, but it also means that a single neuron can be activated by disparate, seemingly unrelated words like- bank, dòng sông, and caterpillar.
This makes llms very difficult to interpret without getting as granular as single neuron activation. You can include some regularization(methods that seek to reduce complexity and overfitting) to constrain the neuron to accept fewer words or concepts.
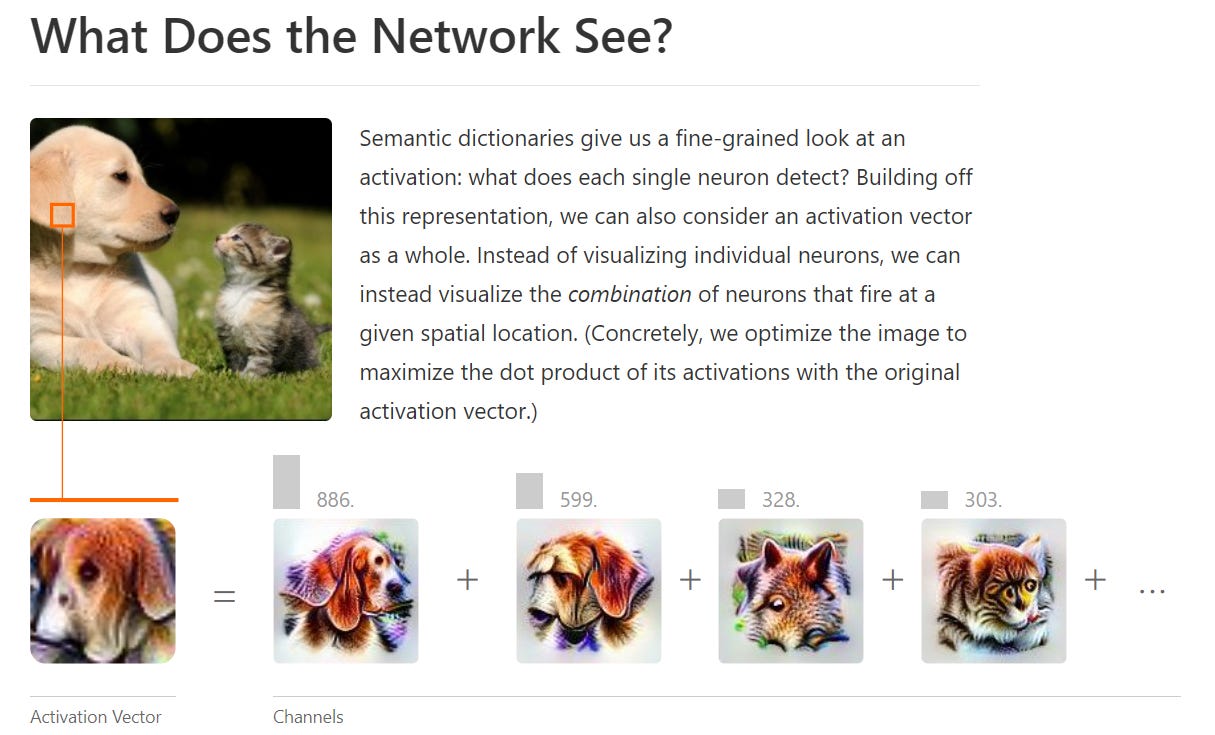
A true magician never reveals their secrets!
“We certainly have not solved interpretability.” -Sam Altman
Companies like Google and Google Brain have been doing research on neural network explainability for years, even before the 2017 Transformers paper, but companies have been a bit conspicuously silent as of late, with exception of Anthropic, who are producing excellent research on attempting to decompose and interpret large language models using sparse autoencoders (these transform input data into representations where most elements are zero, highlighting only the most important features).
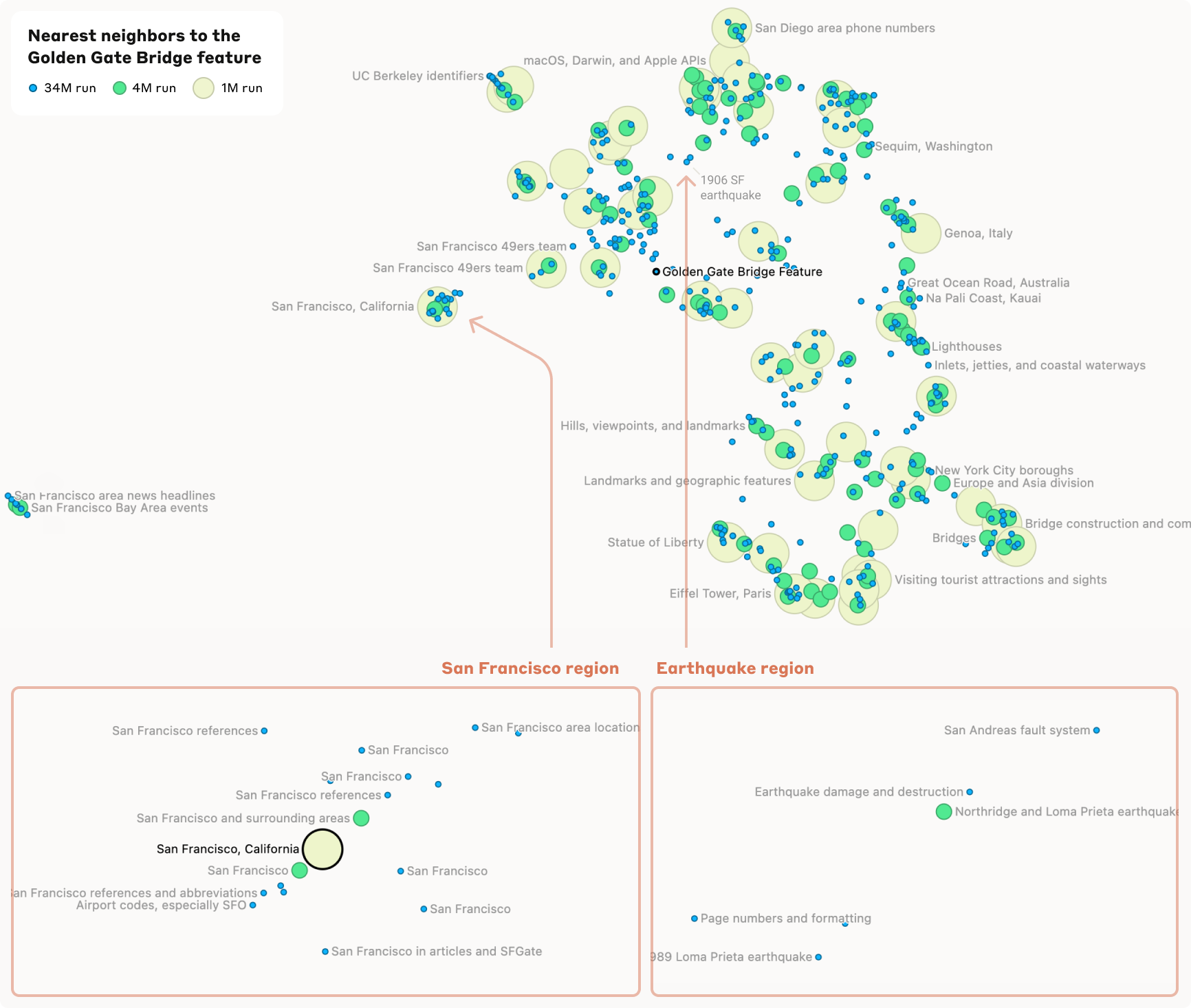
Super cool interactive feature here to explore the feature “Golden Gate Bridge”. A feature in an llm is a meaningful attribute or representation derived from the input data that the model uses to make decisions. :
Money
This is a race. There’s gold in them thar hills! AI explainability doesn’t currently offer a lot of ROI.
Move fast and break things, just ship it, crush your enemies and see them driven before you. Worry about AI explainability later.
But this approach has a short half-life.
Soon, government and industry regulatory bodies are going to step in and ask these companies to explain how the magic is done.
It’s been mostly quiet, crickets and tumbleweeds punctuated by staccato overreach(band name?) like California SB 1047 , but the regulatory landscape around AI explainability is fast evolving.
Without stringent regulations mandating explainability, companies don’t feel pressured to invest heavily in this area. But…they will.
Regulation is coming.
The Finale
Well my friends, I have to admit. It’s been a great show so far.
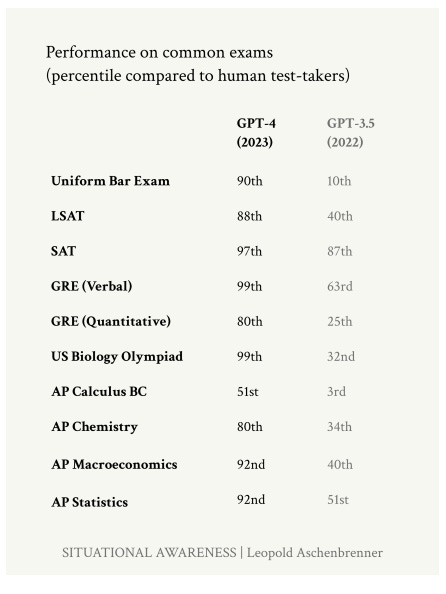
“GPT-2 to GPT-4 took us from ~preschooler to ~smart high-schooler abilities in 4 years.”1 (debatable but interesting take)
A recent iteration of GPT 4 resoundly beats human test-takers in almost all areas :
So, what will be the next great AI magic trick?
Fully agentic AI systems?
AI that is uniformly smarter than us?
Maybe the greatest trick so far will be finally learning how all this magic was done.
Don’t slow down.
from- https://situational-awareness.ai/wp-content/uploads/2024/06/situationalawareness.pdf